An Empirical Evaluation of Accounting Income Numbers
会计收益数据的经验评价
一、引言
(一)研究背景
会计理论家通常通过会计实务与特定分析模型的一致程度来评价其有用性。
这种方法缺点:忽略了世界知识的一个重要来源,即模型的预测与观察到的行为的一致程度。

完全分析式研究存在的问题:
无法确定一个理论是否包含所有与之相关的有证据支持的假设;不能解释那些基于无法证实的前提结论的预测能力;因为考虑了不同方面而得到不同结论之间的差异也无法分析。

完全分析式研究认为收入数据不能被实质性地定义,它们缺乏“意义”,效用值得怀疑。

(二)本文
作者认为在没有进一步的实证研究的情况下,得出缺乏实质性意义就意味着缺乏效用的结论是不妥的。

本文通过现有年度净盈余数据的内容和发表时间,来表现会计报表上盈余数据的有用性。
二、实证研究
(一)研究的重要前提:资本市场理论
1. capital markets are both efficient and unbiased.(资本市场既有效又公正)
2. the information reflected in income numbers is useful.(盈余数据中反应的信息是有用的)
(二)研究方法:将会计收益与股票价格联系起来、关注特定公司的独有信息

(三)公司平均每股盈余变动的原因

(四)J公司收益变化OLS模型
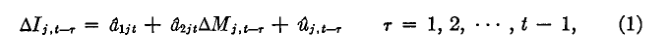
(五)市场反应
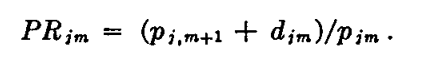


(六)一些计量经济学问题
1. 关于模型(1)

2. 关于模型(2)
(七)总结
定义两个盈余预测模型:
1. regression model:选择盈余的两种计量方式[net income and EPS, variables (1) and (2)]
2. naive model:选择盈余的一种计量方式[EPS, variable (3)]
三、数据

样本公司数据的选取标准:
(1)每家公司在1946-1966年盈余数据都能在Compustat数据库中获得。
(2)财政年度在12月31日结束。
(3)至少100个月的股票价格数据能够在CRSP数据库中获取。
(4)《华尔街日报》年报公告日可以获得。
研究分析了从1957年开始至1965年共9个财政年度。
特殊的选择标准可能降低了结果的一般性。但是,样本中的261家公司都具有重要意义,以及采用不同样本对这次研究重复试验,得到的结果与现在的结果一致。
表 1 相关系数平方分布的十分位数、公司和市场收入的变化

在当前这个样本中,位于中部的公司的盈余变化水平的25%左右与市场指数变化有关。
表 2 收入回归残差中一阶自相关系数分布的十分位数
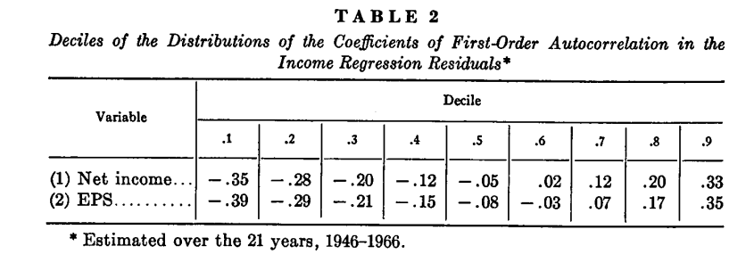
误差中自相关性小,模型预测精确度较高。
表 3 公告日期的时间分布

在整个样本期间,财政年度结束与年度报告发布之间的时间间隔在稳定下降。
表4:股票报酬回归的相关系数平方的十分位数、股票残差的一阶自相关系数

第二个回归模型
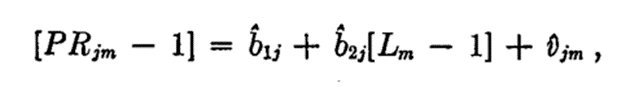
四、研究结果
(一)基本研究结果
将年度报告的宣布日所在的月份定义为0,第M月份的非正常业绩指数:


最上面:描绘了由所有公司所有年份所建构的三个投资组合,它们的收益预测误差对于三个变量中的任意一个都是正的。
最下面:描绘了由所有公司所有年份所建构的三个投资组合,它们的收益预测误差对于三个变量中的任意一个都是负的。
中间:包含了样本中所有公司的所有年份的一个单一的投资组合的情况。
结论:未预期盈余变动的符号为正时,API大于1,未预期盈余变动的符号为负时,API小于1。第一种结果可能会对股票收益的随机扰动项的分布比较敏感。
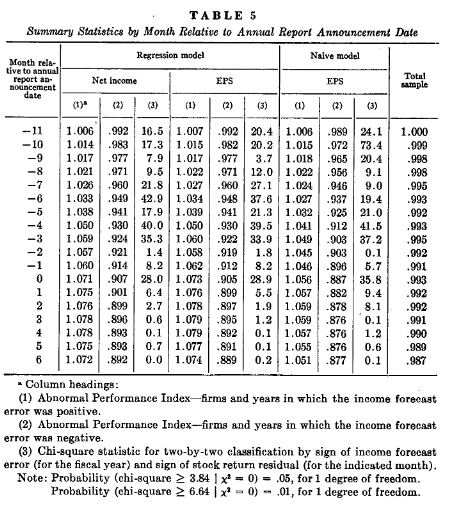
由关于未预期盈余的信号和未预期股票报酬率的信号的一对一卡方统计结果可知:在接近年度报告公布的多数月份中,收益预测误差信号与股票收益率残差的信号之间是有关系的。
(二)概况
1.以上两种结果都证明包含在每年的会计收益数据中的信息是有用的,因为实际收益和预期收益不同的话,市场通常就会朝着和预测收益误差相同的方向作出反应。
2.收益报告中所包含的大部分信息在年度收益报告报出之前已经被市场所预测到了。在收益数据报告月份,真实的收益数据并没有引起任何非正常业绩指数的异常波动。这种有这些指数的持续信号以及它们绝对值的单调增加而揭示出的漂移持续性,表明不仅仅是市场在报告公布之前12个月就开始对收益误差的预测,而且在之后的整年中都在持续成功的做这件事。
(三)特别的结果
1.两个回归模型变量结果之间看起来差异不是很大。变量(2)所得出的结果严格证实了由变量(1)得出的结果,然而当这两个变量得出的有关收益预测误差信号的结果不同时,变量(2)的结果会更加真实一些。
幼稚模型适合于那些有负预测误差的公司的证券组合。
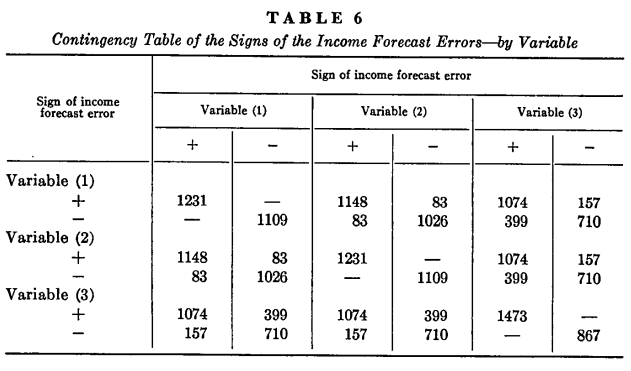
2.由所有公司所有年份计算出的非正常业绩指数向下的漂移反映出了一个计算误差。这个误差产生于:K个月的偏差至少体现在K-1次的和的协方差上。因为协方差是负的,所以这个误差也是负的。
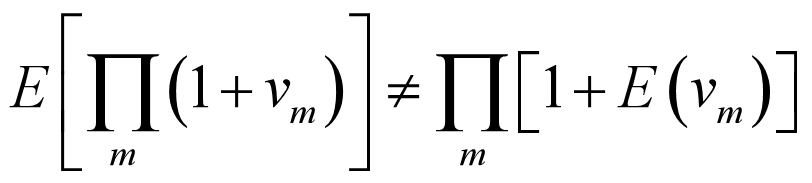
3.作者同样用了收益的替代变量来作回归分析并得出了相应的结果。(a)现金流(用营业收入来估计), 以及(b)非重复性项目前的净收入。没有一个变量能像净收益和EPS那样成功的预测股票收益残差的信号。
4.表5中API的值和卡方统计量都表明,至少对变量(3)来说,收益预测误差的信号与股票收益残差的信号之间的关系会在每年年报报出之前至少持续两个月。
(1)第一个可能的解释是市场收益指数在一些公司报告出他们的收益数据之前都是不确定的。然而这一解释很容易就会被排除,因为如果公司的年报是在一年的一月份的话它们这一年的数据将会从样本中被剔除掉,尽管卡方值是降低的,但并不会影响图1所显示的总体的API的规律。
(2)第二个解释是年报的日期会存在随机的误差。但是这一解释同样很容易就会被排除。因为所有报告日的数据都来自于华尔街日报指数,它已通过华尔街日报核对。
(3)第三个解释是初步报告在没有完成之前是不可能被市场所获得。不幸的是这一问题并不能被一个替代的假设单独解析。
因此我们的结论是和其它证据相一致的:至少是在交易成本之内,市场会对收益数据作出毫无偏差的反应。
(四)年度净收入相对于其他信息来源的价值
这部分主要从净收益所包含信息的相对重要性,以及对收益报告的及时性进行评估
1. 总信息
如果已经实现的回报与期望回报之间的差额,也就是剩余回报,被认为是新信息的价值,个别股票的新月份信息的价值,由给定月份的异常报酬率(股票报酬率的残差)的绝对值决定。关于普通公司所有月度信息的平均价值由下式给出(信息在报告前12个月收到)。TI代表总的信息。在样本中,对所有普通的企业和年份,这个总和是0.731.
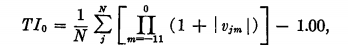
2. 净信息
对于任何一只特定的股票,月份间的某些信息将被抵消,有关平均的股票的信息净值的价值(信息在报告前12个月收到)由下式给出。NI表示净信息。这个总和是0.165。
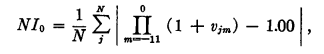
3. 收益信息
如果接受了未预期盈余变化的模型,那么包含在年度收益数据中的信息价值可以由从前12月到前一个月的平均价值增长来估计,其中价值增量的平均数是从所有企业和年份构建的。由预测误差的符号来划分两个投资组合由以下公式给出,其中II代表收益信息,N1和N2分别代表收益预测误差为正数和为负数出现的次数。变量1、2、3计算出的结果分别是0.081,0.083,0.077.
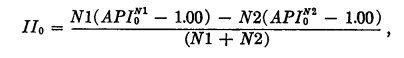
从以上数据中,我们可以得出结论
(1)约75%[(0.731 -0.165) /0.731]的所有资料的价值似乎是相互抵消的,这反过来又意味着约有25%的资料仍然存在。
(2)剩下的25%,大约一半[49%,50%,47%](由0.081/0.165, 0.083 /0.165, 0.077/0.165这三个变量分别计算得到)与报告收入中的信息相关联。
(3)年度会计盈余公告月未预料到的报告收益中的信息不超过10%至15%(12%、11%和13%)。
研究的局限性
(1)没有考虑月末发生交易时股票价格同时变化
(2)没有考虑数据中存在误差
(3)股价具有“离散型”
(4)预计误差模型的无效性
(5)收益预期误差的系统偏差,这说明“真的”收益预测误差的错误分类是不可避免的
五、结果
结论:本文最初的目的是通过检查现有会计盈余数据的信息内容和及时性来评估其有用性,根据研究结果可以看出在一年中获得的所有关于单个公司的信息中,有一半以上被记录在当年的信息收入数字中,所以内容上可观,但是在及时性方面,年度收入报告不是十分及时,其中的大部分内容(大约85%至90%)都被更及时的捕捉到。
需要进一步研究的问题:①市场如何预期净收益的变化,②中期报告和股息公告这些更及时的有什么帮助,有何作用?③未预期的收益变化程度(不仅仅是符号)与相关股票价格调整的关系?
